📌 Leçon - 13
Maîtrisez l'Overfitting, l'Underfitting et la Validation Croisée
Techniques avancées pour évaluer et optimiser vos modèles de Machine Learning
🎯 Concepts Clés à Maîtriser
Biais (Bias)
Erreur due aux hypothèses simplificatrices du modèle
Variance
Sensibilité du modèle aux fluctuations de l'échantillon d'entraînement
Compromis Biais-Variance
Équilibre entre sous-adaptation et sur-adaptation
Validation Croisée
Technique robuste d'évaluation des performances
Overfitting (Sur-adaptation)
Définition : Phénomène où un modèle apprend trop bien les données d'entraînement (y compris le bruit et les détails non pertinents), ce qui dégrade sa performance sur de nouvelles données.
Haute Variance Faible Biais
💡 Exemple Concret : Reconnaissance d'images
Un modèle de classification d'images qui :
- Atteint 99% de précision sur l'ensemble d'entraînement
- N'obtient que 65% sur l'ensemble de test
- A appris des artefacts spécifiques aux images d'entraînement (comme un filigrane présent seulement sur certaines images)
🔍 Signes d'Overfitting
- Performance d'entraînement très supérieure à la performance de test
- Modèle trop complexe (beaucoup de paramètres par rapport aux données)
- Courbes d'apprentissage qui divergent (entraînement continue à s'améliorer tandis que test stagne ou se dégrade)
Causes Principales
- Modèle trop complexe
- Données d'entraînement insuffisantes
- Entraînement trop long (pour les modèles itératifs)
- Features non pertinentes ou redondantes
Solutions
- Régularisation (L1/L2)
- Early stopping
- Augmentation des données
- Simplification du modèle
- Dropout (pour les réseaux de neurones)
🧪 Détection d'Overfitting en Pratique
Règle empirique : Un écart de plus de 10-15% entre entraînement et test peut indiquer un overfitting.
Underfitting (Sous-adaptation)
Définition : Phénomène où un modèle est trop simple pour capturer les motifs sous-jacents dans les données, résultant en de mauvaises performances à la fois sur les données d'entraînement et de test.
Faible Variance Haut Biais
💡 Exemple Concret : Prédiction de prix
Un modèle linéaire pour prédire des prix immobiliers qui :
- N'atteint que 60% de précision sur l'entraînement
- Performance similaire sur le test
- Ne capture pas les relations non-linéaires évidentes (comme l'effet de la superficie qui n'est pas purement linéaire)
🔍 Signes d'Underfitting
- Performances médiocres à la fois sur entraînement et test
- Modèle trop simple (peu de paramètres)
- Résidus élevés et motifs non capturés dans les prédictions
- Courbes d'apprentissage plates (peu d'amélioration avec plus d'entraînement)
Causes Principales
- Modèle trop simple
- Features insuffisantes ou non informatives
- Trop de régularisation
- Entraînement insuffisant (pour les modèles itératifs)
Solutions
- Augmenter la complexité du modèle
- Feature engineering plus poussé
- Réduire la régularisation
- Augmenter la durée d'entraînement
- Utiliser des modèles plus puissants
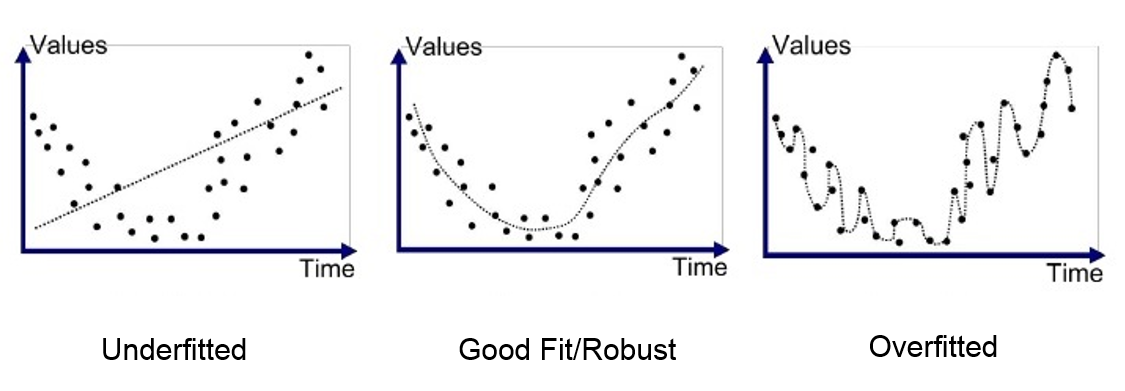
📉 Courbes d'Apprentissage Typiques
Underfitting
Haute erreur sur entraînement et test
Bon équilibre
Erreur similaire et faible sur les deux ensembles
Overfitting
Faible erreur d'entraînement mais haute erreur de test
Compromis Biais-Variance
Définition : Relation fondamentale en machine learning qui décrit le compromis entre la capacité d'un modèle à s'adapter aux données d'entraînement (faible biais) et sa capacité à généraliser à des données non vues (faible variance).
Théorie Fondamental
Cette décomposition mathématique montre que pour minimiser l'erreur totale, nous devons trouver le bon équilibre entre biais et variance.
📊 Impact de la Complexité du Modèle
| Complexité | Biais | Variance | Résultat |
|---|---|---|---|
| Faible | Haut | Faible | Underfitting |
| Modérée | Moyen | Moyen | Bon équilibre |
| Élevée | Faible | Haut | Overfitting |
⚖️ Stratégies pour Trouver l'Équilibre
Pour réduire le biais
- Augmenter la complexité du modèle
- Ajouter des features pertinentes
- Réduire la régularisation
Pour réduire la variance
- Réduire la complexité du modèle
- Augmenter les données d'entraînement
- Ajouter de la régularisation
- Utiliser le bagging
Validation Croisée
Définition : Technique robuste d'évaluation des modèles qui consiste à diviser plusieurs fois le jeu de données en ensembles d'entraînement et de validation pour obtenir une estimation plus fiable des performances.
Évaluation Robuste
🧩 Types de Validation Croisée
k-Fold
Division en k sous-ensembles égaux, chaque sous-ensemble sert une fois de validation
Avantage : Toutes les données sont utilisées pour l'entraînement et la validation
Stratifiée
Préserve la distribution des classes dans chaque fold
Utile pour : Données déséquilibrées
Leave-One-Out (LOO)
k = n (chaque observation est un fold)
Avantage : Maximise l'utilisation des données
Inconvénient : Coûteux pour grands datasets
🐍 Implémentation avec scikit-learn
Avantages
- Meilleure utilisation des données limitées
- Estimation plus robuste des performances
- Détection plus fiable de l'overfitting
- Permet de comparer différents modèles objectivement
Limitations
- Coût computationnel plus élevé
- Pas toujours nécessaire pour les très grands datasets
- Plus complexe à mettre en œuvre que simple split train/test
📝 Bonnes Pratiques
- Choix de k : 5 ou 10 folds sont généralement un bon compromis
- Mélange des données : Toujours shuffle les données avant de créer les folds
- Stratification : Utiliser la version stratifiée pour les problèmes de classification avec déséquilibre
- Répétabilité : Fixer un random_state pour des résultats reproductibles
- Métriques : Choisir des métriques adaptées au problème (accuracy, F1, ROC-AUC, etc.)
🔧 Cas Pratique : Optimisation d'un Modèle
1. Diagnostic Initial
Évaluer les performances via validation croisée et analyser les courbes d'apprentissage pour identifier overfitting/underfitting
2. Stratégie d'Amélioration
Choisir des techniques adaptées au problème identifié (régularisation, augmentation de complexité, etc.)
3. Validation
Vérifier l'impact des changements via une nouvelle validation croisée
📈 Workflow Complet en Python
🧠 Quiz Final : Testez Votre Compréhension
1. Votre modèle a 98% d'accuracy sur l'entraînement mais seulement 65% sur le test. Quel est le problème ?
2. Quelle technique n'aide PAS à réduire l'overfitting ?
📝 Voir les réponses
Réponse 1 : Overfitting (grand écart entre performance entraînement et test)
Réponse 2 : "Ajouter des paramètres" (cela augmenterait l'overfitting)
🎯 Conclusion & Bonnes Pratiques
1. Diagnostiquez d'abord
Utilisez les courbes d'apprentissage et la validation croisée pour identifier overfitting/underfitting avant d'intervenir
2. Choisissez la bonne stratégie
Overfitting → Simplifiez le modèle ou régularisez
Underfitting → Augmentez la complexité ou feature engineering
3. Validez systématiquement
Toujours évaluer les changements via validation croisée pour des résultats robustes
📋 Checklist d'Optimisation
- ☑️ Analyser les courbes d'apprentissage
- ☑️ Implémenter la validation croisée (k=5 ou 10)
- ☑️ Pour overfitting: régularisation, dropout, early stopping
- ☑️ Pour underfitting: features additionnelles, modèle plus complexe
- ☑️ Toujours garder un jeu de test final pour évaluation finale
- ☑️ Documenter toutes les expérimentations et résultats
📚 Ressources Complémentaires
Livres
- "Elements of Statistical Learning" - Hastie, Tibshirani, Friedman
- "Machine Learning Yearning" - Andrew Ng
Articles
- "Understanding the Bias-Variance Tradeoff" - Scott Fortmann-Roe
- Scikit-learn documentation on model evaluation
Outils
- Scikit-learn learning_curve et validation_curve
- TensorBoard pour visualisation des modèles DL
Commentaires
Enregistrer un commentaire